论文阅读_图像生成-pix2pix:Image-to-Image Translation with Conditional Adversarial Networks
这篇文章主要的立足点在于:
认为所有的图像到图像的转换操作,都可以用一个 GAN 进行训练拟合。
基于此,该文探讨了一个通用的 cGAN 网络来实现诸如从轮廓图像重建目标、给图像上色、根据标签地图生成原图等一系列
任务目标。
先来张图一睹为快:

哦对不起放错了,是这张:

这就是这篇文章提出的 cGAN 的诸多应用的一个展示。
当然,对应于不同的应用,还是需要不同的数据集来进行训练,然后才能实现不同的任务,所不变的只是 cGAN 这个模型结构。
说到这里,大家应该也感觉到,该文的核心论点,其实也就是构造了一个通用模型~~
到底如何?君且安坐,且看下文如何分解~~
1. why
大多数图像处理、计算机图形学以及计算机视觉的问题其实都相当于把一个输入图像 “翻译” 成一张输出图像。
就好像一个语言概念可以被翻译成汉语、法语、意大利语、赛博坦语等,一个视觉场景应该同样也能被渲染成RGB、梯度场、边界图、语义标签图等。
因此,就好像机器翻译一样,作者也定义了一个自动的 image-to-image translation 任务,即:
只要给定足够的训练数据,就能够把一种场景表达 翻译 成另一种场景表达。
这就是这篇论文的目标:
真実はいつも一つ!构建一个通用的框架。
那又为何要用 GAN 呢?而且还要用 Conditional GAN ?
其实这个也就是 GAN 所出现的契机了:
CNN虽然大行其道,但是想要一个好的结果,就必须需要设计一个好的loss.
换句话说,你要告诉CNN要训练个啥,要学习个啥。
但就好像迈达斯王一样,你也不能随便许愿,而是要谨小慎微地设计这个loss。
既然如此,我们就要问了:我可不可以跳过这个loss设计呢?我直接告诉这个模型我想要啥结果不就行了么?
恭喜你,这就是GAN!
那为啥是conditional GAN呢?
因为我们想要图像到图像的转换:以一个图像为条件,生成一个对应的图像。
那么问题来了:我怎么让模型根据我的输入图像来生成对应的输出图像呢?
答案就是:我在训练时,让generator不只是看到随机噪声点,同时也看到对应的输入图像。
which is conditional GAN~
2. how
故事讲完了,剩下的就是怎么圆这个故事了。
2.1. objective
众所周知,GAN所学习的是:$G: z → y$,而conditional GAN则是:$G: {x,z}→y$。
其中x是输入图像,z是随机噪声向量,y是输出图像。
而conditional GAN的目标函数为:
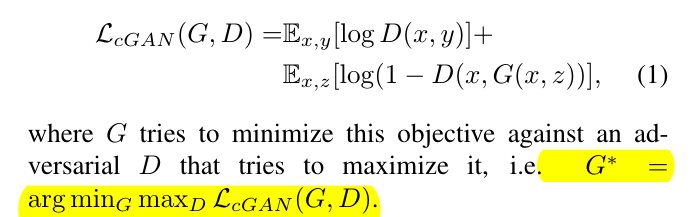
同时,为了让generator能够更鲁棒,还额外加了个L1 distance loss:
$L_{L1}(G) = E_(x,y,z)[||y-G(x,z)||_1]$ (居然手打了个公式,可把我牛逼坏了)
于是,最终的目标函数为:

2.2. network architecture
2.2.1. generator with skips
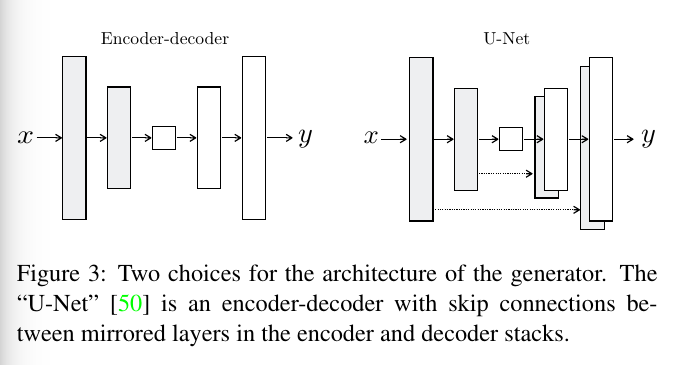
关于image-to-image translation, 一个本质性的特征就是把高分辨率的输入图像映射成高分辨率的输出图像。
所以生成器(generator)的架构应该是encoder-decoder,而文章这里用了类似U-Net的网络架构,加上了skip connections.如图:
2.2.2. markovian discriminator(PatchGAN)
来张图:

如图,L1 loss,以及L2 loss,在图像生成时会造成模糊的结果,这是众所周知的。
但换个角度想,其实它们也能准确的捕捉低频信息对不对?
也正因为此,论文用L1 loss来加强低频信息的准确性,同时这也使得GAN discriminator也就可以专注于高频结构的塑造。
是不是很机智?
而对于高频信息,我们就可以只关注于图像的局部区域(local patches)。
这也是PatchGAN的由来——只在patch层面上对结构信息进行惩罚。
discriminator是学习判别一张图的每个$NxN$的patch是否是真的,比如这篇论文采用的$N=70$,一个简单的效果图如下:

对于patchGAN,一个显而易见的好处就是可以用在任意大于训练图像尺寸的图像上,比如你可以在256x256上训练,然后用在512x512上。
2.2.3. optimization and inference
这个优化应该属于常规操作了:
D和G各轮流训练一轮,同时把generator的目标函数捯饬了一下,从
最小化$log(1-D(x, G(x,z)))$变成了最大化$logD(x,G(x,z))$。
在预测时,generator也同样加上了dropout,而且也对测试时的batch加了batch normalization。
当然,这是为了噪声足够随机嘛,又不是分类任务,当然可以加。
3. results
故事讲完了,也圆好了,剩下的就是大家喜闻乐见的有图有真相环节了。
这个乏善可陈,无非是在什么数据集上,采用什么评价标准,我们超越了state-of-the-art多少多少。
只有图片会让大家看的很爽~~
那就放图吧:





好啦,都放了5张图啦~~
如果还没看够的话,可以点击查看论文的官网:phillipi/pix2pix
4. bonus!
看了这么多功能,是不是手痒?
好想自己动手试一下啊有没有?
但是又不耐烦下源码装环境跑程序怎么办?
不用怕!
贴心的我发现了一个在线体验网址!:image-to-image interactive demo
开不开心?惊不惊喜?
是不是激动地想要赏我两个铜板?

5. end
以上,就是这篇pix2pix的阅读所得。
欢迎大家指摘讨论~~
微信公众号:璇珠杂俎(也可搜索oukohou),提供本站优质非技术博文~~

regards.
oukohou.
既已览卷至此,何不品评一二: