论文阅读-人脸生成_StyleGAN-A_Style-Based_Generator_Architecture
StyleGAN,提出了一个新的 generator architecture,号称能够控制所生成图像的高层级属性(high-level attributes),如 发型、雀斑等;并且生成的图像在一些评价标准上得分更好;同时随论文开源了一个高质量数据集:FFHQ, 包含 7W 张 $1024*1024$ 高清人脸照。7W 张啊朋友们,简直就是宝藏啊~
1. Style-based generator
开门见山,直说论文所提出的 style-based generator。不同于常见的直接把 latent code 输入给 generator 的输入层的做法,这篇论文摒弃了输入层,
转而添加了一个非线性映射网络:$f:Z \to W$,如下图:
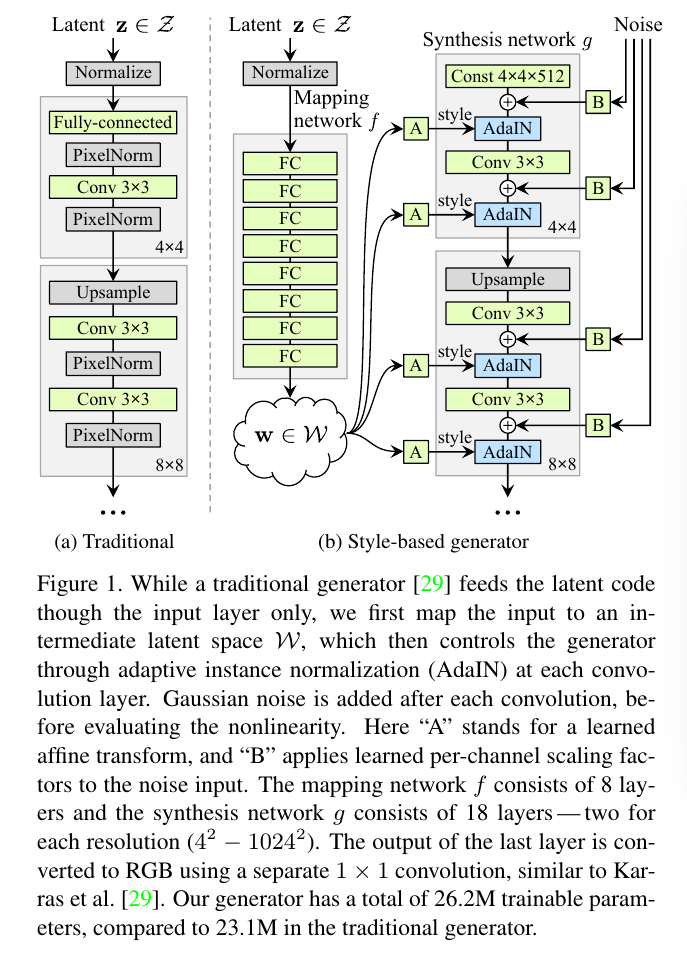
图中, Z 和 W 的维度都是512维, A 是一个仿射变换(Affine transform), B 是每个channel的高斯噪声的系数,而AdaIN则是:
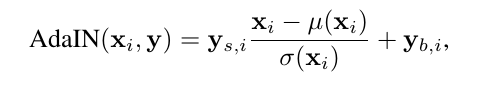
图中,$y_(s,i)$和$y_(b,i)$则是w经过A变换之后得到的$y=(y_s, y_b)$,$(y_(s,i),y_(b,i))$对的个数与每一层feature map的channel数相同。
好了,总结一下,说的这么玄乎,其实就是把输入z用了8层全连接层做了个非线性变换,得到512维的w,然后再用个仿射变换A得到每一层normalization
所需的scale和shift,也就是$y_(s,i)$和$y_(b,i)$,在这之前还有个高斯噪声输入。如此而已。
然后作者认为,因为每一个卷积层都被归一化,并且经过了$y_(s,i)$和$y_(b,i)$的scale、shift,所以generator所生成的图片的style就是受
$y=(y_s, y_b)$来控制的,即所谓style-based generator。而且因为每一层都会有归一化,所以这些操作只能影响最终的结果一部分。
2. Style mixing
为进一步促使这些style来局部化其控制效果,作者又采用了mixing regularization。其实也很简单,作者的style-based generator不是有个
8层卷积的非线性变换么,这下提前计算两个图像的变换结果$w_1$、$w_2$,然后在生成过程中随机取$w_1$或者$w_2$的值进行操作。结果如下图:

然后作者说这些不同的styles控制了不同的有意义的high-level attributes。
个人感觉,这些styles确实对结果有影响,但要说不同的style控制不同的属性,未免有点牵强。不过是从结果强推结论罢了。
3. Stochastic variation
作者说,人有很多随机属性,例如头发、胡须、雀斑等,所以一个好的generator自然也要能够实现stochastic variation。
而作者认为,传统的generator的输入就只有输入层,所以generator自身必须寻找一种生成伪随机数的方式,而这会消耗网络的capacity,并且很难隐藏生成的
信号的周期性。
而这时,作者的高斯噪声输入B就派上了用场了。如下图:

4. Separation of global effects from stochasticity
然后就是作者声称的,其style A 和高斯噪声 B 能够分别控制生成图像的不同level: A 控制全局属性,如姿态、身份等,而 B 控制一些相对次要的
随机变量,如不同的发型、胡须分布等等。
其实这也不难理解,观察generator结构中,如图,再放一次:
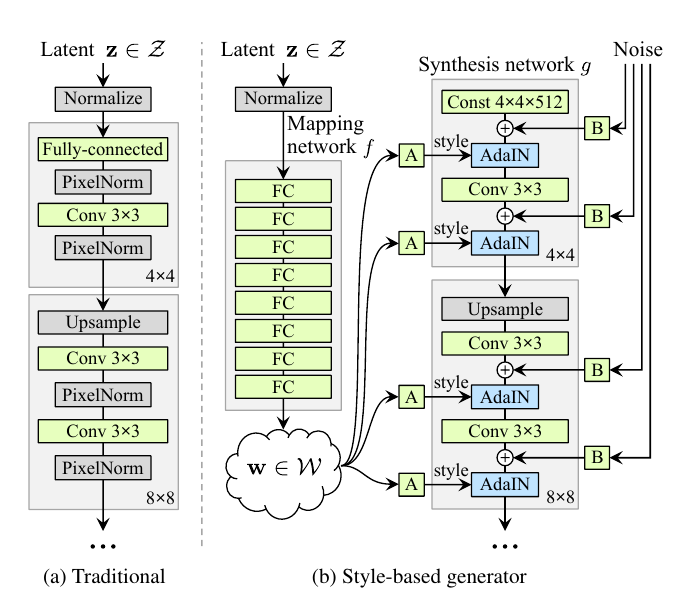
A的作用是对所有的feature map进行scale和shift,自然影响结果也是全局性的;
而B只是加到了每层的像素上,紧接着就被AdaIN给归一化了……自然只能影响很小一部分,而在人脸生成这个task上,这个很小一部分恰巧表现为头发、胡须、雀斑等的分布而已。
5. Experiments
然后就是一些对比试验了,大同小异,乏善可陈,直接放大家喜闻乐见的图片吧:



6. End
时隔将近一个月,终于又更新了一篇啦~~
开心~~
完结撒花~~
微信公众号:璇珠杂俎(也可搜索oukohou),提供本站优质非技术博文~~

regards.
oukohou.
既已览卷至此,何不品评一二: